
一、图的基本概念
1、有向图和无向图
图由顶点和连接顶点的边组成,根据其边是否有方向性分为两类:有向图和无向图。
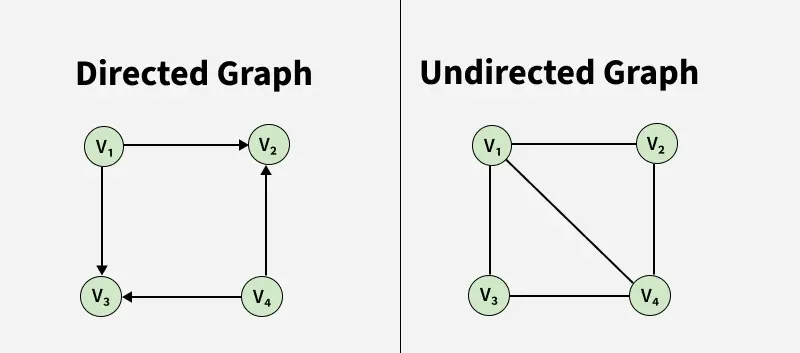
左图中 V1 有一条指向 V2 的边,说明 V1 可以到达 V2,但 V2 无法到达 V1;
右图中 V1 和 V2 之间的边没有方向性,说明它们可以互相到达,在实现层面,可以把无向图模拟为双向的有向图。
2、连通图和非连通图
根据顶点之间的连通性,图又可以分为连通图和非连通图。
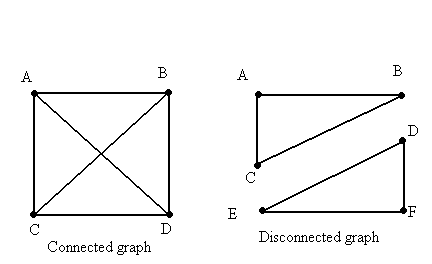
左图中的每个顶点都可以通过边与其他顶点相连,说明这是一个连通图;
右图中的顶点被分成了两个部分,左边的顶点之间相互连通,右边也相互连通,但他们之间没有任何连接,说明这是一个非连通图。
如果图中并非任意两个顶点之间都存在路径,则该图为非连通图。
3、再看二叉树
二叉树也是一种特殊的图结构
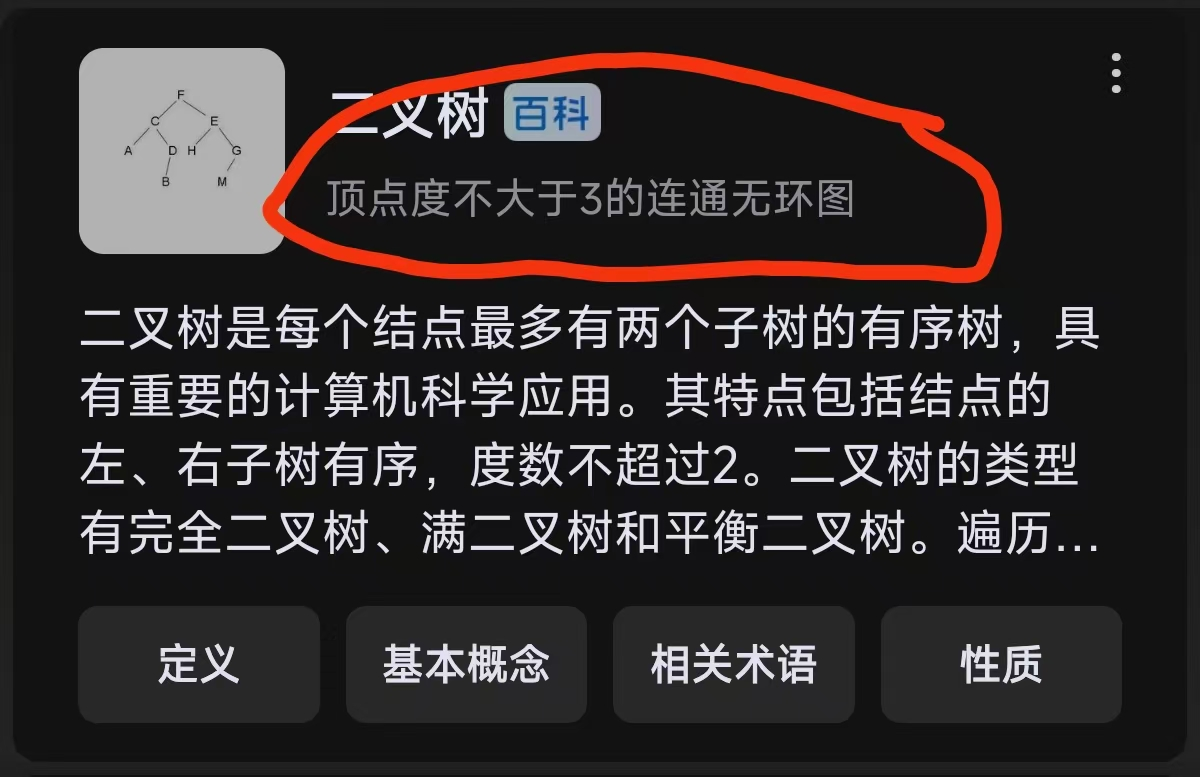
二叉树是一种特殊的图结构:
- 从图论角度看,若将二叉树视为无向图,它是「连通无环图」;
- 从数据结构角度看,二叉树是「每个节点最多有两个子节点的有根有序树」,边具有方向性(父节点指向子节点);
- 在无向图视角下,节点的度不超过 3(最多 2 个子节点边 + 1 个父节点边)。
这里引用 《hello 算法》 中的一张图片:
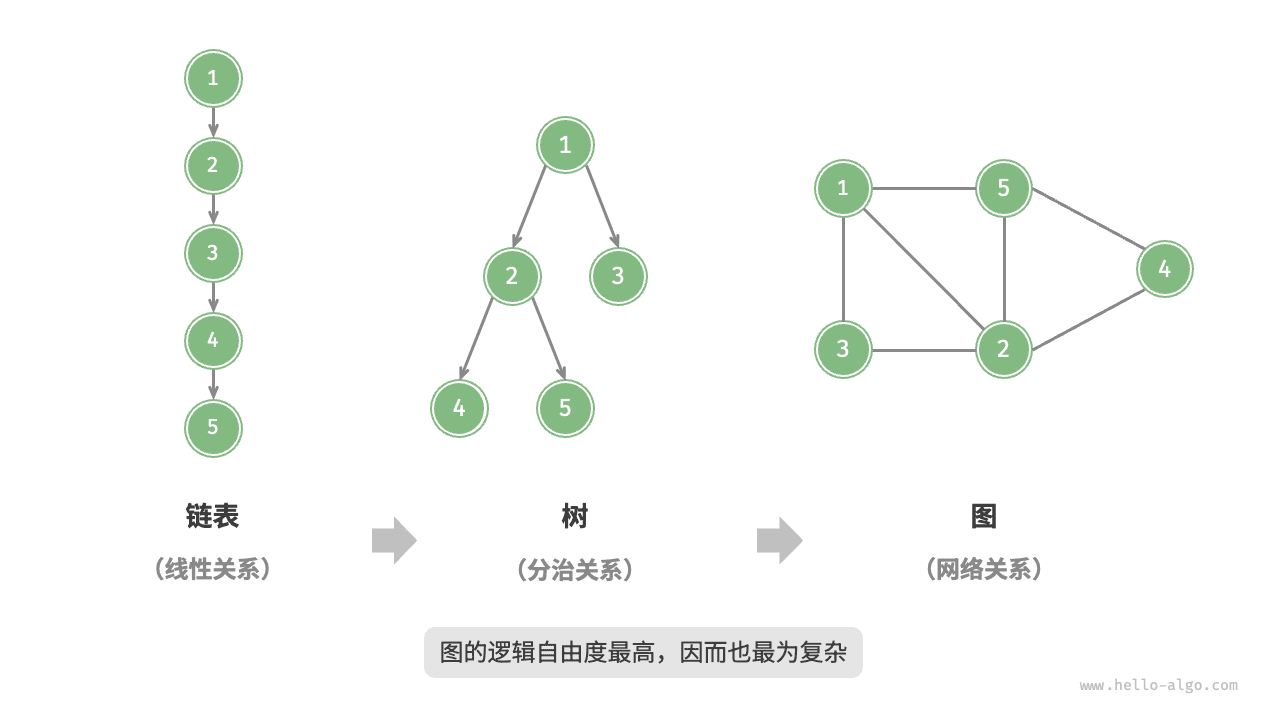
在树结构中,只允许父节点指向子节点,不存在子节点指向父节点的情况,子节点之间也不会互相连接;
而图中没有那么多限制,顶点之间可以相互指向,形成复杂的网络结构。
二、图的代码实现
对于链表和树结构,我们可以用节点(Node)和指针来实现;对于图结构,我们也可以用类似的方式来实现。
1、邻接链表(Adjacency List)
我们知道图是由顶点和边组成,每个顶点可以有多个边连接到其他顶点。
因此我们可以创建一个大小为 n 的数组来存放 n 个顶点的信息。
而每个顶点中包含着一条链表,链表中存储着与该顶点相连的所有顶点的信息。
这样我们就可以通过数组和链表的组合来实现图结构了,教材中叫作邻接表(Adjacency List,也称邻接链表)。
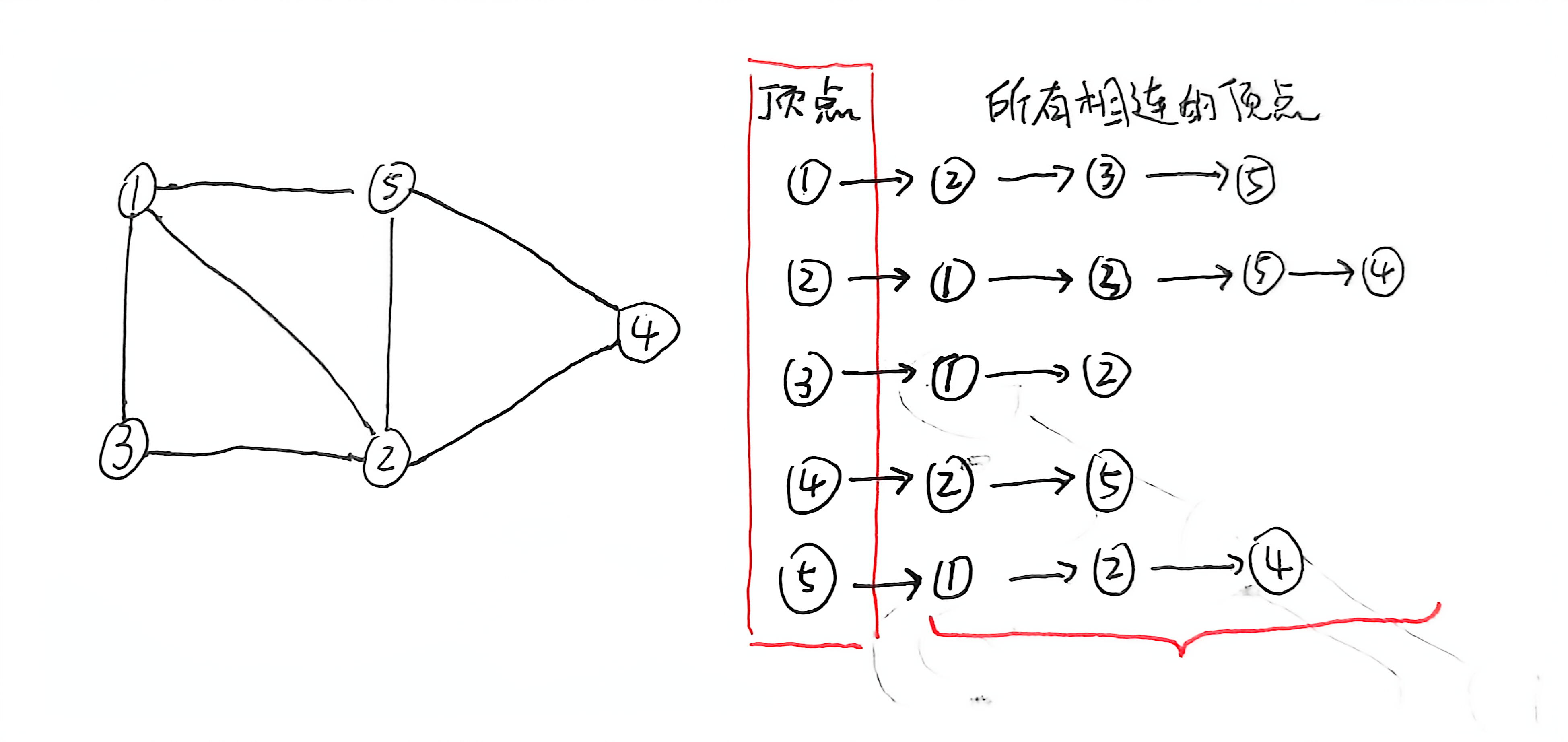
这里你有可能会问:链表的顺序会不会影响图的结构?
其实链表的顺序并不影响图的结构,因为图的结构是由顶点和边的连接关系(邻接关系)决定的,而不是由链表中元素的顺序决定的。
拿下面的有向图来说:
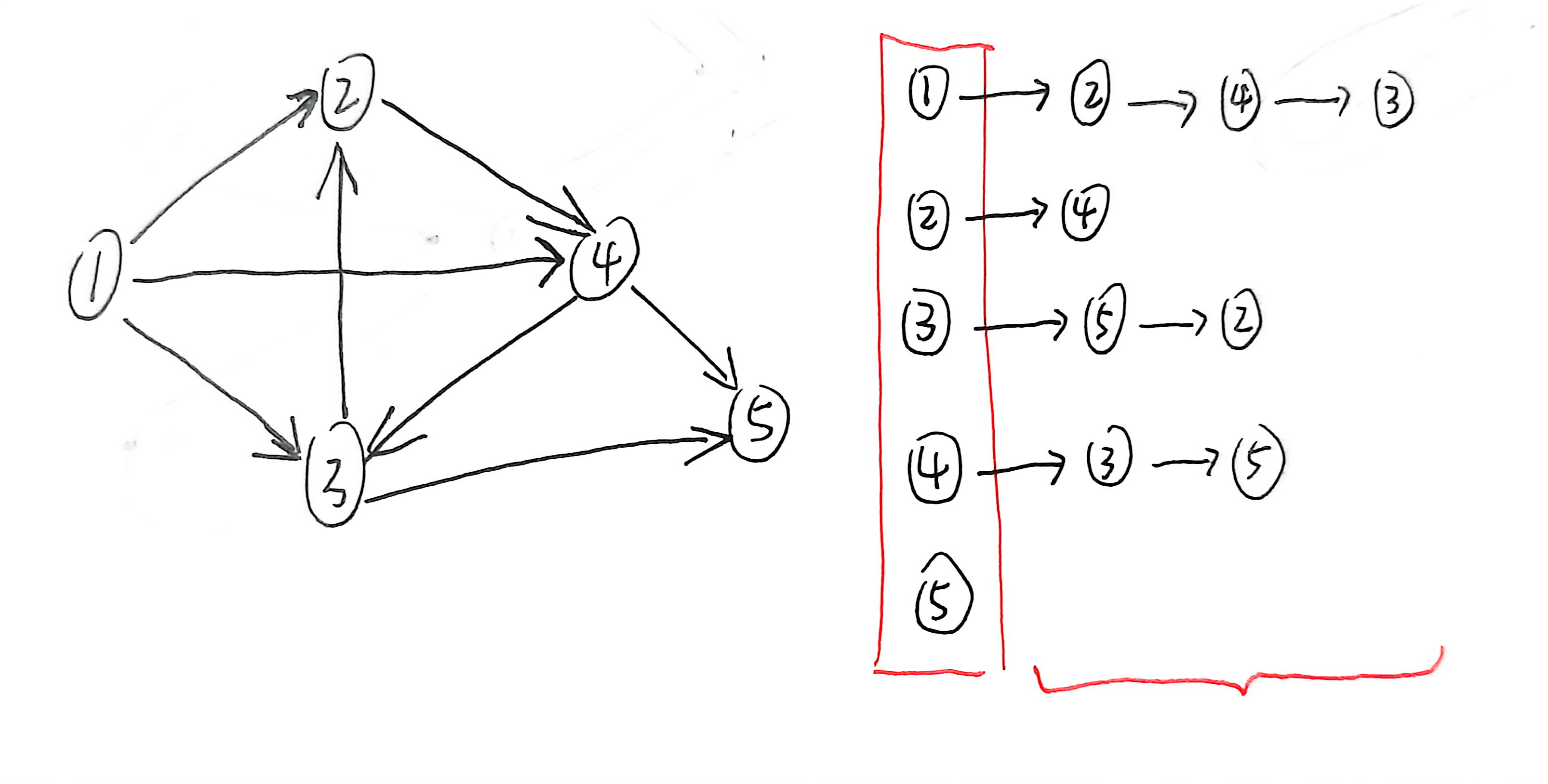
所以不管是有向图还是无向图,我们都可以用邻接链表来实现。
代码实现:
就拿上面这个有向图来说,图中的顶点和边的关系如下:
| 顶点 | 指向的顶点 |
|---|---|
| 顶点 1 | 顶点 2、顶点 3 和 顶点 4 |
| 顶点 2 | 顶点 4 |
| 顶点 3 | 顶点 2 和 顶点 5 |
| 顶点 4 | 顶点 3 和 顶点 5 |
| 顶点 5 | 没有指向任何顶点 |
我们可以用一个数组来存储每个顶点的信息,每个元素是一个链表,链表中存储着与该顶点相连的所有顶点的信息。
#include <iostream>
#include <vector>
#include <list>
using namespace std;
class Graph {
private:
vector<list<int>> adjList_; // 邻接链表
int numVertices_; // 顶点数量
public:
Graph(int numVertices) : numVertices_(numVertices) {
adjList_.resize(numVertices); // 初始化邻接链表
}
// 添加边(from 指向 to)
void addEdge(int from, int to) {
// 校验顶点合法性(1 ~ numVertices_)
if (from < 1 || from > numVertices_ || to < 1 || to > numVertices_) {
cout << "顶点编号超出范围!" << endl;
return;
}
adjList_[from - 1].push_back(to - 1); // 转成 0 开始的索引存储
}
// 打印图的邻接链表
void printGraph() {
for (int i = 0; i < numVertices_; ++i) {
cout << "顶点 " << i + 1 << ":"; // 显示 1 开始的编号
for (int neighbor: adjList_[i]) {
cout << " " << neighbor + 1; // 邻接顶点也显示 1 开始
}
cout << endl;
}
}
};
int main() {
Graph graph(5); // 创建一个有 5 个顶点的图(编号 1 ~ 5)
/*
| 顶点 | 指向的顶点 |
| ----- | ----------------------- |
| 顶点 1 | 顶点 2、顶点 3 和 顶点 4 |
| 顶点 2 | 顶点 4 |
| 顶点 3 | 顶点 2 和 顶点 5 |
| 顶点 4 | 顶点 3 和 顶点 5 |
| 顶点 5 | 没有指向任何顶点 |
*/
// 添加边(用 1 开始的编号)
graph.addEdge(1, 2); // 顶点 1 指向 顶点 2
graph.addEdge(1, 3); // 顶点 1 指向 顶点 3
graph.addEdge(1, 4); // 顶点 1 指向 顶点 4
graph.addEdge(2, 4); // 顶点 2 指向 顶点 4
graph.addEdge(3, 2); // 顶点 3 指向 顶点 2
graph.addEdge(3, 5); // 顶点 3 指向 顶点 5
graph.addEdge(4, 3); // 顶点 4 指向 顶点 3
graph.addEdge(4, 5); // 顶点 4 指向 顶点 5
// 打印图的邻接链表
graph.printGraph();
return 0;
}
2、邻接矩阵(Adjacency Matrix)
这里你有可能会发现问题:对于有向图来说,顶点 1 指向顶点 2,因此我们只用操作顶点 1 的链表就可以了;
对于无向图来说,顶点 1 和顶点 2 之间是连接(双向)的关系,因此我们需要同时操作顶点 1 和顶点 2 的链表。
我们可以使用另外一种方式来实现图结构,那就是邻接矩阵。
邻接矩阵同样适用于有向图和无向图。对于无向图,由于边是双向的,其邻接矩阵一定是对称矩阵。
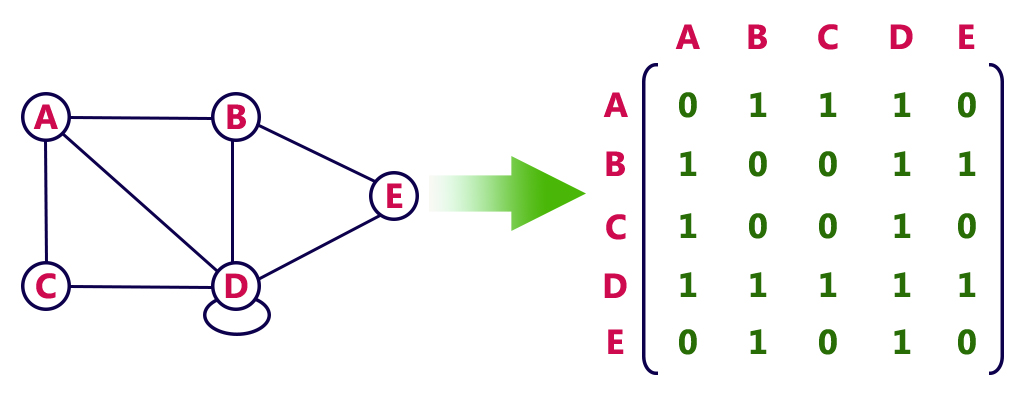
我们创建一个 n x n 的二维数组来存储图的信息,其中 n 是顶点的数量。
- 行索引代表起点顶点
- 列索引代表终点顶点
第 i 行 j 列的元素表示顶点 i 是否指向顶点 j,如果存在边则为 1,否则为 0。
比如说上图中,[0][0] 的元素为 0, 表示顶点 A 没有指向自己;
[3][2](第四行第三列)的元素为 1, 表示顶点 D 指向顶点 C,而 [2][3](第三行第四列)的元素为 1, 表示顶点 C 指向顶点 D。
对于无向图,邻接矩阵是对称的,因为如果顶点 i 和 j 之间有边,那么顶点 j 和 i 之间必然也有边(无向边的双向性)。
无向图邻接矩阵代码实现:
#include <iostream>
#include <vector>
using namespace std;
class Graph {
private:
vector<vector<int>> adjMatrix_; // 邻接矩阵
int numVertices_; // 顶点数量
public:
Graph(int numVertices) : numVertices_(numVertices) {
adjMatrix_.resize(numVertices, vector<int>(numVertices, 0)); // 初始化
}
// 为无向图添加边:顶点 u 和 v 之间建立连接
void addEdge(int u, int v) {
// 校验顶点合法性(1 ~ numVertices_)
if (u < 1 || u > numVertices_ || v < 1 || v > numVertices_) {
cout << "顶点编号超出范围!" << endl;
return;
}
adjMatrix_[u - 1][v - 1] = 1; // 标记 u 到 v 有边
adjMatrix_[v - 1][u - 1] = 1; // 标记 v 到 u 有边(无向图双向性)
}
// 打印图的邻接矩阵
void printGraph() {
cout << " ";
for (int i = 0; i < numVertices_; ++i) {
cout << i + 1 << " "; // 显示 1 开始的编号
}
cout << endl;
for (int i = 0; i < numVertices_; ++i) {
cout << i + 1 << " "; // 显示 1 开始的编号
for (int j = 0; j < numVertices_; ++j) {
cout << adjMatrix_[i][j] << " ";
}
cout << endl;
}
}
};
int main() {
Graph graph(5); // 创建一个有 5 个顶点的图(编号 1 ~ 5)
/*
邻接矩阵
1 2 3 4 5
1 0 1 1 1 0
2 1 0 0 1 0
3 1 0 0 0 1
4 1 1 0 0 1
5 0 0 1 1 0
*/
// 添加边(用 1 开始的编号)
graph.addEdge(1, 2); // 顶点 1 和 顶点 2 之间建立连接
graph.addEdge(1, 3); // 顶点 1 和 顶点 3 之间建立连接
graph.addEdge(1, 4); // 顶点 1 和 顶点 4 之间建立连接
graph.addEdge(2, 4); // 顶点 2 和 顶点 4 之间建立连接
graph.addEdge(3, 5); // 顶点 3 和 顶点 5 之间建立连接
graph.addEdge(4, 5); // 顶点 4 和 顶点 5 之间建立连接
// 打印图的邻接矩阵
graph.printGraph();
return 0;
}
3、效率对比
对于有 n 个顶点和 m 条边的图:
| 邻接链表 | 邻接矩阵 | 说明 | |
|---|---|---|---|
| 添加边 | O(1) | O(1) | 只需要在对应的位置添加边的信息 |
| 删除边 | O(n) | O(1) | 邻接链表需要遍历链表找到边,邻接矩阵直接修改对应位置 |
| 查询边 | O(n) | O(1) | 邻接链表需要遍历链表找到边,邻接矩阵直接查询对应位置 |
| 添加顶点 | O(1) | O(n) | 邻接链表只需要添加一个新的链表,邻接矩阵需要扩展二维数组 |
| 删除顶点 | O(n + m) | O(n^2) | 邻接链表需要删除对应的链表和相关边,邻接矩阵需要删除对应行列并调整矩阵大小 |
| 空间复杂度 | O(n + m) | O(n^2) | 邻接链表只存储实际存在的边,邻接矩阵需要存储所有可能的边 |
三、图的遍历算法
1、深度优先搜索(DFS)
和二叉树的深度优先搜索一样,比如说前序遍历
4
/ \
2 6
/ \ / \
1 3 5 7
从根节点 4 开始,先访问当前节点,然后一直访问左子节点,直到访问到叶子节点时回溯到上一个节点,再访问右子节点,直到回溯到根节点为止。
对于图来说,没有根节点,并且顶点之间关系复杂,所以根据创建边的顺序不同,DFS 的访问顺序也会不同。
同时因为图中可能存在环,所以我们需要一个 visited 数组来记录已经访问过的顶点,避免重复访问。
// 以下函数属于 Graph 类,省略类定义,仅展示核心逻辑
void DFS(int vertex, vector<bool>& visited) {
visited[vertex] = true; // 标记当前顶点为已访问
cout << "访问顶点 " << vertex + 1 << endl; // 输出当前访问的顶点(显示 1 开始的编号)
// 遍历与当前顶点相邻的所有顶点
for (int neighbor: adjList_[vertex]) {
if (!visited[neighbor]) { // 如果邻接顶点未被访问过
DFS(neighbor, visited); // 递归访问邻接顶点
}
}
}
验证代码:
int main() {
Graph graph(5); // 创建一个有 5 个顶点的图(编号 1 ~ 5)
// 创建图的边(用 1 开始的编号)
graph.addEdge(1, 2); // 顶点 1 指向 顶点 2
graph.addEdge(1, 3); // 顶点 1 指向 顶点 3
graph.addEdge(1, 4); // 顶点 1 指向 顶点 4
graph.addEdge(2, 4); // 顶点 2 指向 顶点 4
graph.addEdge(3, 2); // 顶点 3 指向 顶点 2
graph.addEdge(3, 5); // 顶点 3 指向 顶点 5
graph.addEdge(4, 3); // 顶点 4 指向 顶点 3
graph.addEdge(4, 5); // 顶点 4 指向 顶点 5
vector<bool> visited(5, false); // 初始化 visited 数组,默认所有顶点未访问
cout << "深度优先搜索(DFS)访问顺序:" << endl;
graph.DFS(0, visited); // 从顶点 1(索引 0)开始访问
return 0;
}
最后输出的是:
深度优先搜索(DFS)访问顺序:
访问顶点 1
访问顶点 2
访问顶点 4
访问顶点 3
访问顶点 5
因为 DFS 的访问顺序取决于边的创建顺序(创建顺序影响邻接链表存储顺序,进而影响遍历顺序),
从上面创建图的边的代码来看,1 指向 2, 2 指向 4, 4 指向 3, 3 指向 5,所以遍历顺序就是 1 -> 2 -> 4 -> 3 -> 5。
2、广度优先搜索(BFS)
广度优先搜索是先访问当前顶点,然后访问所有与当前顶点相邻的顶点,再依次访问这些相邻顶点的相邻顶点,直到访问完所有顶点为止。
是一种由近及远的访问方式。
同样因为图中可能存在环,所以我们也需要一个 visited 数组来记录已经访问过的顶点,避免重复访问。
// 以下函数属于 Graph 类,省略类定义,仅展示核心逻辑
void BFS(int startVertex, vector<bool>& visited) {
queue<int> q; // 创建一个队列来存储待访问的顶点
visited[startVertex] = true; // 标记起始顶点为已访问
q.push(startVertex); // 将起始顶点加入队列
while (!q.empty()) {
int vertex = q.front(); // 获取队列头部的顶点
q.pop(); // 从队列中移除该顶点
cout << "访问顶点 " << vertex + 1 << endl; // 输出当前访问的顶点(显示 1 开始的编号)
// 遍历与当前顶点相邻的所有顶点
for (int neighbor: adjList_[vertex]) {
if (!visited[neighbor]) { // 如果邻接顶点未被访问过
visited[neighbor] = true; // 标记邻接顶点为已访问
q.push(neighbor); // 将邻接顶点加入队列
}
}
}
}
看起来和 DFS 的代码很像,但它们的访问顺序是不同的。
int main() {
Graph graph(5); // 创建一个有 5 个顶点的图(编号 1 ~ 5)
// 创建图的边(用 1 开始的编号)
graph.addEdge(1, 2); // 顶点 1 指向 顶点 2
graph.addEdge(1, 3); // 顶点 1 指向 顶点 3
graph.addEdge(1, 4); // 顶点 1 指向 顶点 4
graph.addEdge(2, 4); // 顶点 2 指向 顶点 4
graph.addEdge(3, 2); // 顶点 3 指向 顶点 2
graph.addEdge(3, 5); // 顶点 3 指向 顶点 5
graph.addEdge(4, 3); // 顶点 4 指向 顶点 3
graph.addEdge(4, 5); // 顶点 4 指向 顶点 5
vector<bool> visited(5, false); // 初始化 visited 数组,默认所有顶点未访问
cout << "深度优先搜索(DFS)访问顺序:" << endl;
graph.DFS(0, visited); // 从顶点 1(索引 0)开始访问
fill(visited.begin(), visited.end(), false); // 重置 visited 数组,准备进行 BFS
cout << "\n广度优先搜索(BFS)访问顺序:" << endl;
graph.BFS(0, visited); // 从顶点 1(索引 0)开始访问
return 0;
}
输出结果:

DFS 的访问顺序受边的创建顺序影响;
BFS 保证按层级(距离)访问顶点,但在同一层内的访问顺序仍然取决于邻接链表中顶点的存储顺序。
我们创建的边的顺序是:
1 指向 2, 1 指向 3, 1 指向 4, 2 指向 4, 3 指向 2, 3 指向 5, 4 指向 3, 4 指向 5。
| 步骤 | 队列状态 | 操作 | 访问顺序 |
|---|---|---|---|
| 初始 | [1] | 标记 1 已访问,入队 | |
| 1 | [2,3,4] | 1 出队,输出 1;邻居 2,3,4 未访问,标记并入队 | 1 |
| 2 | [3,4] | 2 出队,输出 2;邻居 4 已访问(在队列中) | 1,2 |
| 3 | [4,5] | 3 出队,输出 3;邻居 2 已访问,5 未访问,标记并入队 | 1,2,3 |
| 4 | [5] | 4 出队,输出 4;邻居 3,5 都已访问 | 1,2,3,4 |
| 5 | [] | 5 出队,输出 5;无邻居 | 1,2,3,4,5 |
因此 BFS 的访问顺序是 1 -> 2 -> 3 -> 4 -> 5。
3、应用场景
拿 200. 岛屿数量 来说,
给定一个由 '1'(陆地)和 '0'(水)组成的二维网格,计算岛屿的数量。岛屿总是被水包围,并且每个岛屿只能由水平或垂直方向上相邻的陆地连接形成。
我们可以把这个二维网格看作一个图结构,其中每个陆地格子是一个顶点,如果两个陆地格子在水平或垂直方向上相邻,那么它们之间就有一条边。
DFS 解法(ACM 代码):
#include <bits/stdc++.h>
using namespace std;
const int dx[4] = {-1, 1, 0, 0};
const int dy[4] = {0, 0, -1, 1};
vector<vector<char>> grid;
int n, m; // 行数 n,列数 m
void dfs(int x, int y) {
// 越界 或 不是陆地,直接返回
if (x < 0 || x >= n || y < 0 || y >= m || grid[x][y] != '1') {
return;
}
grid[x][y] = '0'; // 标记为已访问
// 递归遍历四个方向
for (int i = 0; i < 4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
dfs(nx, ny);
}
}
int main() {
// 先读行数 n,列数 m,再读 n 行字符串(每行 m 个字符)
cin >> n >> m;
grid.resize(n, vector<char>(m));
for (int i = 0; i < n; i++) {
string s;
cin >> s;
for (int j = 0; j < m; j++) {
grid[i][j] = s[j];
}
}
int count = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == '1') {
count++;
// 从当前陆地格子开始,DFS 将整个岛屿的陆地格子都标记为 '0',避免重复计数
dfs(i, j);
}
}
}
cout << count << endl;
return 0;
}
BFS 解法(ACM 代码):
#include <bits/stdc++.h>
using namespace std;
const int dx[4] = {-1, 1, 0, 0};
const int dy[4] = {0, 0, -1, 1};
vector<vector<char>> grid;
int n, m; // 行数 n,列数 m
void bfs(int x, int y) {
queue<pair<int, int>> q;
q.push({x, y});
grid[x][y] = '0'; // 标记为已访问
while (!q.empty()) {
pair<int, int> curr = q.front();
int cx = curr.first;
int cy = curr.second;
q.pop();
// 遍历四个方向
for (int i = 0; i < 4; i++) {
int nx = cx + dx[i];
int ny = cy + dy[i];
// 越界 或 不是陆地,跳过
if (nx < 0 || nx >= n || ny < 0 || ny >= m || grid[nx][ny] != '1') {
continue;
}
grid[nx][ny] = '0'; // 标记为已访问
q.push({nx, ny}); // 将相邻的陆地格子加入队列
}
}
}
int main() {
// 先读行数 n,列数 m,再读 n 行字符串(每行 m 个字符)
cin >> n >> m;
grid.resize(n, vector<char>(m));
for (int i = 0; i < n; i++) {
string s;
cin >> s;
for (int j = 0; j < m; j++) {
grid[i][j] = s[j];
}
}
int count = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == '1') {
count++;
// 从当前陆地格子开始,BFS 将整个岛屿的陆地格子都标记为 '0',避免重复计数
bfs(i, j);
}
}
}
cout << count << endl;
return 0;
}
两种解法的复杂度分析:
| DFS | BFS | 说明 | |
|---|---|---|---|
| 时间复杂度 | O(n × m) | O(n × m) | 每个格子最多被访问一次 |
| 空间复杂度 | O(n × m) | O(n × m) | BFS 队列在二维网格中的峰值为 O(min(n, m)) |