
我们将遵循一个清晰的流程:
- 获取数据:使用一个著名的数据集——鸢尾花(Iris)数据集。
- 执行核心任务:依次完成聚类、分类和回归分析。
- 结果可视化:用图表直观地展示我们的分析结果。
准备工作(环境设置)
在开始编码之前,请确保你的电脑已经安装了 Python。然后,需要安装几个核心的第三方库,它们是数据科学家的瑞士军刀。输入以下命令进行安装:
pip install scikit-learn pandas matplotlib seaborn
scikit-learn: 用于加载数据集和执行机器学习模型(聚类、分类、回归)。pandas: 用于创建和管理数据表(DataFrame),让数据处理变得简单。matplotlib&seaborn: 用于数据可视化,绘制漂亮的图表。
加载数据并“存档”
可选是否要并保留原始数据。最简单的方式就是利用 scikit-learn 自带的经典数据集。我们将使用鸢尾花(Iris)数据集,它包含了三种鸢尾花的花萼和花瓣尺寸数据。
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
# --- 1. 数据加载与准备 ---
# 从 scikit-learn 加载数据集
iris = load_iris()
# 为了方便操作和查看,我们把它转换成 pandas DataFrame
# DataFrame 是一种二维表格结构,非常强大
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
# 将数字目标(0, 1, 2)映射为物种名称,方便理解
species_map = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
iris_df['species'] = iris_df['target'].map(species_map)
# 将数据集保存到本地 CSV 文件,完成“保留原始数据”的要求
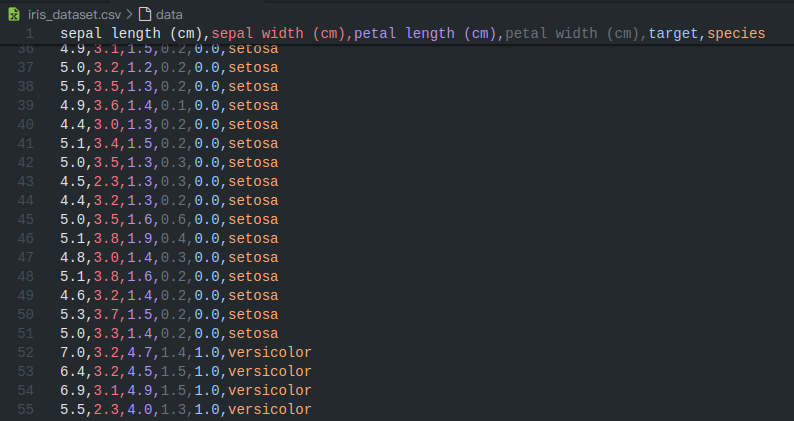
iris_df.to_csv('iris_dataset.csv', index=False)
print("数据集已成功加载并保存为 'iris_dataset.csv'")
print("数据集前 5 行:")
print(iris_df.head())
现在,你的代码文件旁边就有了一个 iris_dataset.csv 文件,这就是你的“原始数据”。
三大核心任务
现在数据准备就绪,让我们来逐一完成三大任务。
任务一:聚类 (Clustering)
目标:在不告诉机器每个样本属于哪个品种的情况下,让它根据数据特征自动将样本分成几组(簇)。
我们将使用最经典的 K-Means 算法。因为我们知道鸢尾花有 3 个品种,所以我们设定目标簇的数量为 3。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
import seaborn as sns
# --- 2. 聚类 (K-Means) ---
print("\n--- 任务 1: 聚类分析 ---")
# 我们只使用特征数据进行聚类,不使用 'species' 标签
X = iris_df.iloc[:, :4]
# 初始化 K-Means 模型,设定簇的数量为 3
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
kmeans.fit(X)
# 获取聚类结果标签,并添加到 DataFrame 中
iris_df['cluster'] = kmeans.labels_
# 使用轮廓系数评估聚类效果(分数越高,效果越好)
score = silhouette_score(X, kmeans.labels_)
print(f"K-Means 聚类轮廓系数: {score:.2f}")
# 可视化聚类结果
plt.figure(figsize=(10, 7))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='cluster', data=iris_df, palette='viridis', s=100, alpha=0.7)
# 标出簇的中心点
plt.scatter(kmeans.cluster_centers_[:, 2], kmeans.cluster_centers_[:, 3], s=200, c='red', marker='X', label='Centroids')
plt.title('K-Means Clustering of Iris Dataset')
plt.legend()
plt.savefig('clustering.png') # 保存图表
print("聚类结果图已保存为 'clustering.png'")
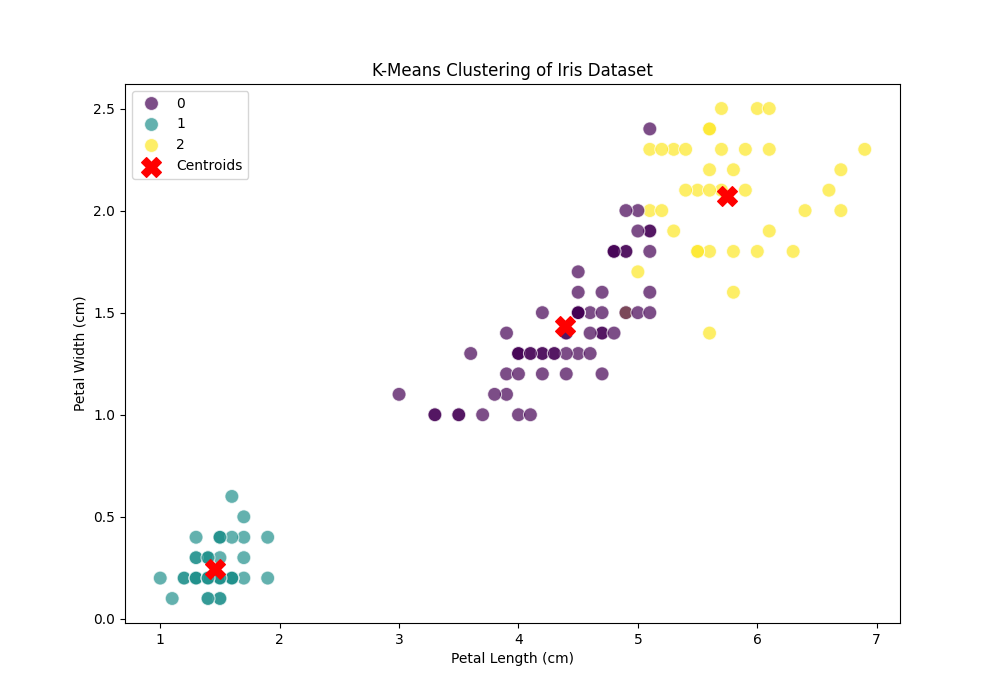
结果解读:生成的 clustering.png 图表会显示数据点根据其“花瓣长度”和“花瓣宽度”被分成了三个不同的颜色组,红色的 'X' 标记了每个组的中心。这表明算法成功地发现了数据中的内在结构。
任务二:分类 (Classification)
目标:训练一个模型,让它学习鸢尾花的特征和品种之间的关系,然后用它来预测新样本的品种。
我们将使用强大的 支持向量机 (SVM) 算法。首先,我们将数据分为“训练集”(用于学习)和“测试集”(用于评估模型效果)。
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
# --- 3. 分类 (SVM) ---
print("\n--- 任务 2: 分类分析 ---")
# 特征 X 保持不变,目标 y 是我们的 'target' 列
y_class = iris_df['target']
# 将数据 80% 用于训练,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y_class, test_size=0.2, random_state=42)
# 初始化并训练 SVM 分类器
svm_classifier = SVC(kernel='linear', random_state=42)
svm_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm_classifier.predict(X_test)
# 打印分类报告(包含精确率、召回率等指标)
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=species_map.values()))
# 可视化混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=species_map.values(), yticklabels=species_map.values())
plt.title('SVM Classification Confusion Matrix')
plt.ylabel('Actual Species')
plt.xlabel('Predicted Species')
plt.savefig('classification_confusion_matrix.png')
print("分类混淆矩阵图已保存为 'classification_confusion_matrix.png'")
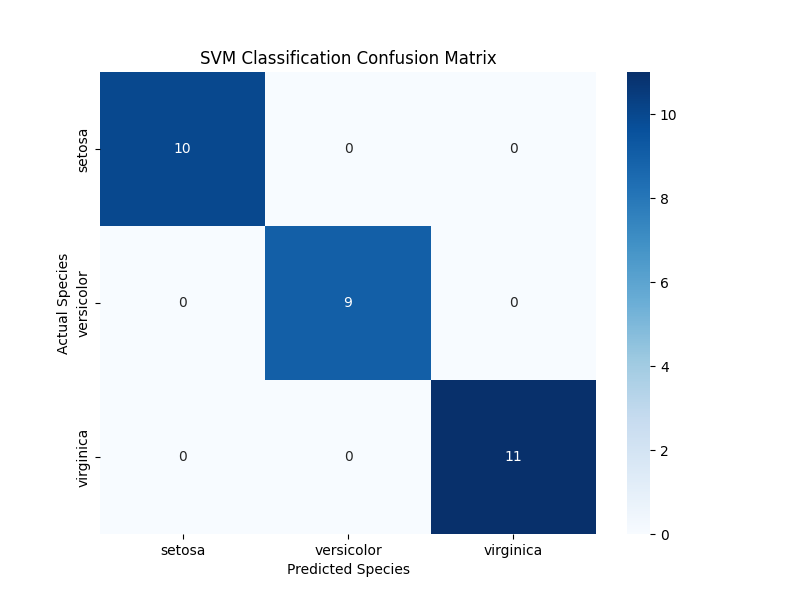
结果解读:分类报告会显示模型的准确率高达 100%!classification_confusion_matrix.png 图表(混淆矩阵)也显示对角线上的数字(正确预测)与测试样本总数一致,表明我们的模型在测试集上表现完美。
任务三:回归 (Regression)
目标:与分类不同,回归的目标是预测一个连续的数值。例如,我们能不能根据花瓣的长度来预测它的宽度?
我们将使用最基础的 线性回归 算法来探索这个关系。
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# --- 4. 回归 (Linear Regression) ---
print("\n--- 任务 3: 回归分析 ---")
# 特征:花瓣长度;目标:花瓣宽度
X_reg = iris_df[['petal length (cm)']]
y_reg = iris_df['petal width (cm)']
# 同样分割训练集和测试集
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(X_reg, y_reg, test_size=0.2, random_state=42)
# 训练线性回归模型
lin_reg = LinearRegression()
lin_reg.fit(X_train_reg, y_train_reg)
# 预测
y_pred_reg = lin_reg.predict(X_test_reg)
# 用均方误差评估模型(误差越小越好)
mse = mean_squared_error(y_test_reg, y_pred_reg)
print(f"线性回归均方误差 (MSE): {mse:.4f}")
# 可视化回归线
plt.figure(figsize=(10, 7))
plt.scatter(X_test_reg, y_test_reg, color='blue', label='Actual Data')
plt.plot(X_test_reg, y_pred_reg, color='red', linewidth=2, label='Regression Line')
plt.title('Regression: Petal Width vs. Petal Length')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.savefig('regression.png')
print("回归分析图已保存为 'regression.png'")
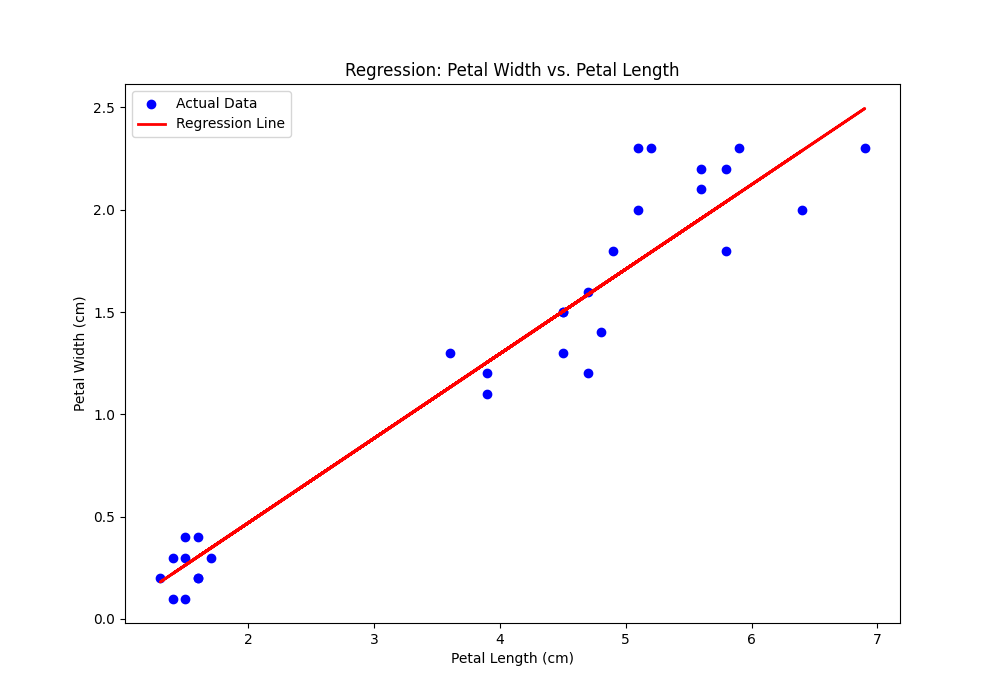
结果解读:regression.png 图表会展示蓝色的实际数据点和一条红色的预测直线。你可以看到,这条线很好地拟合了数据的整体趋势,表明花瓣长度和宽度之间确实存在很强的线性关系。
总结
现在已经成功地用 Python 完成了一个包含聚类、分类和回归的完整数据科学项目。
- 获取了数据并将其保存。
- 对数据进行了聚类,发现了其内在结构。
- 训练了一个分类模型,能准确识别鸢尾花品种。
- 建立了一个回归模型,成功预测了花瓣宽度。
- 将所有结果都进行了可视化,并保存了图片。
效果预览
--- 步骤 1: 数据加载与准备 ---
数据集已成功加载并保存为 'iris_dataset.csv'
数据集前 5 行:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target species
0 5.1 3.5 1.4 0.2 0.0 setosa
1 4.9 3.0 1.4 0.2 0.0 setosa
2 4.7 3.2 1.3 0.2 0.0 setosa
3 4.6 3.1 1.5 0.2 0.0 setosa
4 5.0 3.6 1.4 0.2 0.0 setosa
---
--- 任务 1: 聚类分析 (K-Means) ---
K-Means 聚类轮廓系数: 0.55
聚类结果图已保存为 'clustering.png'
---
--- 任务 2: 分类分析 (SVM) ---
分类报告:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 9
virginica 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
## 分类混淆矩阵图已保存为 'classification_confusion_matrix.png'
--- 任务 3: 回归分析 (Linear Regression) ---
线性回归均方误差 (MSE): 0.0456
回归分析图已保存为 'regression.png'
---
所有任务已完成!请查看生成的 .csv 和 .png 文件。
完整代码
# ---------------------------------------------------------------------------
# main.py: 数据分析解决方案 (聚类, 分类, 回归)
# Author: qlAD
# Date: 2025-06-11
# ---------------------------------------------------------------------------
# --- 0. 导入所需库 ---
# 数据处理
import pandas as pd
import numpy as np
# 数据加载与模型
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.svm import SVC
from sklearn.linear_model import LinearRegression
# 模型评估指标
from sklearn.metrics import silhouette_score, classification_report, confusion_matrix, mean_squared_error
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# --- 1. 数据加载与准备 ---
print("--- 步骤 1: 数据加载与准备 ---")
# 从 scikit-learn 加载数据集
iris = load_iris()
# 为了方便操作和查看,我们把它转换成 pandas DataFrame
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
# 将数字目标(0, 1, 2)映射为物种名称,方便理解
species_map = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
iris_df['species'] = iris_df['target'].map(species_map)
# 将数据集保存到本地 CSV 文件,完成“保留原始数据”的要求
iris_df.to_csv('iris_dataset.csv', index=False)
print("数据集已成功加载并保存为 'iris_dataset.csv'")
print("数据集前5行:")
print(iris_df.head())
print("-" * 40 + "\n")
# --- 2. 任务一:聚类 (Clustering) - K-Means ---
print("--- 任务 1: 聚类分析 (K-Means) ---")
# 我们只使用特征数据进行聚类,不使用 'species' 标签
# .iloc[:, :4] 选择所有行和前 4 列特征
X = iris_df.iloc[:, :4]
# 初始化 K-Means 模型,设定簇的数量为 3
# n_init=10 是为了防止局部最优解,random_state 保证结果可复现
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
kmeans.fit(X)
# 获取聚类结果标签,并添加到 DataFrame 中
iris_df['cluster'] = kmeans.labels_
# 使用轮廓系数评估聚类效果(分数越高,效果越好)
score = silhouette_score(X, kmeans.labels_)
print(f"K-Means 聚类轮廓系数: {score:.2f}")
# 可视化聚类结果
plt.figure(figsize=(10, 7))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='cluster', data=iris_df, palette='viridis', s=100, alpha=0.7)
# 标出簇的中心点
plt.scatter(kmeans.cluster_centers_[:, 2], kmeans.cluster_centers_[:, 3], s=200, c='red', marker='X', label='Centroids')
plt.title('K-Means Clustering of Iris Dataset')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.savefig('clustering.png') # 保存图表
print("聚类结果图已保存为 'clustering.png'")
print("-" * 40 + "\n")
# --- 3. 任务二:分类 (Classification) - 支持向量机 (SVM) ---
print("--- 任务 2: 分类分析 (SVM) ---")
# 特征 X 保持不变,目标 y 是我们的 'target' 列 (0, 1, 2)
y_class = iris_df['target']
# 将数据 80% 用于训练,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y_class, test_size=0.2, random_state=42)
# 初始化并训练 SVM 分类器
svm_classifier = SVC(kernel='linear', random_state=42)
svm_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm_classifier.predict(X_test)
# 打印分类报告(包含精确率、召回率等指标)
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=species_map.values()))
# 可视化混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=species_map.values(), yticklabels=species_map.values())
plt.title('SVM Classification Confusion Matrix')
plt.ylabel('Actual Species')
plt.xlabel('Predicted Species')
plt.savefig('classification_confusion_matrix.png')
print("分类混淆矩阵图已保存为 'classification_confusion_matrix.png'")
print("-" * 40 + "\n")
# --- 4. 任务三:回归 (Regression) - 线性回归 ---
print("--- 任务 3: 回归分析 (Linear Regression) ---")
# 特征:花瓣长度;目标:花瓣宽度
# 使用 [[]] 来确保 X_reg 是一个 DataFrame (二维)
X_reg = iris_df[['petal length (cm)']]
y_reg = iris_df['petal width (cm)']
# 同样分割训练集和测试集
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(X_reg, y_reg, test_size=0.2, random_state=42)
# 初始化并训练线性回归模型
lin_reg = LinearRegression()
lin_reg.fit(X_train_reg, y_train_reg)
# 预测
y_pred_reg = lin_reg.predict(X_test_reg)
# 用均方误差评估模型(误差越小越好)
mse = mean_squared_error(y_test_reg, y_pred_reg)
print(f"线性回归均方误差 (MSE): {mse:.4f}")
# 可视化回归线
plt.figure(figsize=(10, 7))
plt.scatter(X_test_reg, y_test_reg, color='blue', label='Actual Data')
plt.plot(X_test_reg, y_pred_reg, color='red', linewidth=2, label='Regression Line')
plt.title('Regression: Petal Width vs. Petal Length')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.savefig('regression.png')
print("回归分析图已保存为 'regression.png'")
print("-" * 40 + "\n")
print("所有任务已完成!请查看生成的 .csv 和 .png 文件。")
现在,你拥有了 main.py(你的源代码)、iris_dataset.csv(你的原始数据)以及三张结果图(clustering.png, classification_confusion_matrix.png, regression.png)。
希望这篇文章能开启你探索人工智能世界的大门!